An algorithm is basically a set of instructions or steps designed to solve a problem. When it comes to machine learning, algorithms are a bit like smart recipes. They allow computers to learn from data, which means the more data they process, the better they get at making predictions or decisions. For example, an algorithm can help a computer recognize patterns in a bunch of photos to identify which ones contain cats. Over time, as it learns from more and more photos, it gets really good at spotting those cats, even in new pictures it hasn’t seen before
Machine learning algorithms can be categorized into three main types: supervised, unsupervised, and reinforcement learning algorithms. Let’s explore each type, how they work, and their common implementations.
How Do Algorithms Work?
Algorithms typically follow a logical structure consisting of three main steps: Input, Processing, and Output. Let’s explore each step.
1. Input
The first step is input, where the algorithm receives data to work with. This data can come in various forms, such as numbers, text, images, or more complex data structures. In machine learning, input data often includes features (or variables) that describe different aspects of the problem.
2. Processing
In the processing step, the algorithm performs a series of operations on the input data. These operations can vary widely depending on the type of algorithm and the problem it is designed to solve. The goal of this step is to extract patterns, relationships, or insights from the data.
3. Output
The final step is output, where the algorithm produces the desired result based on the processed data. This output can be a prediction, a classification, a cluster of similar items, or any other form of result that solves the original problem.
Types of Machine Learning Algorithms
Machine learning algorithms can be categorized into three main types: supervised, unsupervised, and reinforcement learning algorithms. Let’s explore each type, how they work, and their common implementations.
Supervised Learning Algorithms
In supervised learning, the algorithm is trained on a labeled dataset, which means that each training example is paired with an output label. The goal is to learn a mapping from inputs to outputs.
Common Supervised Learning Algorithms
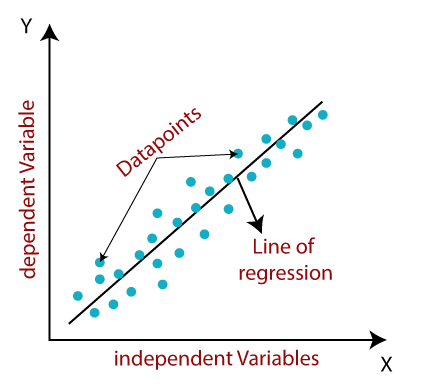
Linear Regression
Linear Regression is a powerful technique for predicting continuous values, based on one or more input features. It works by finding the best-fitting line through data points, capturing the trend in the data. To achieve this, it uses the least squares method, which adjusts the line to minimize the differences between the predicted values and the actual data points.
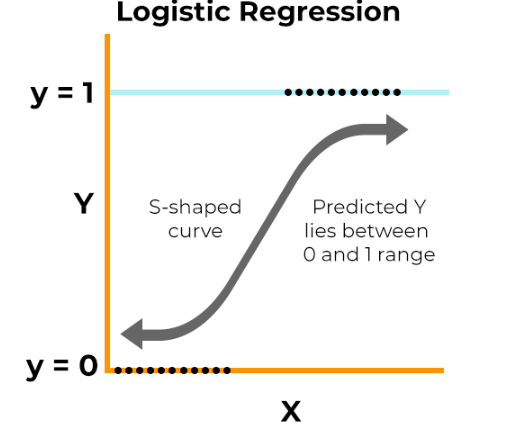
Logistic Regression
Logistic Regression is a technique for tackling binary classification problems, where we need to decide between two classes. It works by modeling the probability that a given input belongs to a particular class using the logistic function, which squashes values between 0 and 1. This helps us determine the likelihood of an input falling into one class over the other. To find the best parameters for the model, Logistic Regression uses maximum likelihood estimation, ensuring the predictions are as accurate as possible.
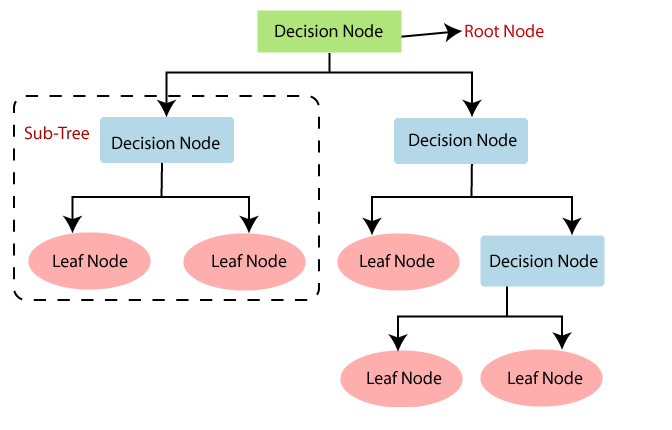
Decision Trees
Decision Trees are versatile models used for both classification and regression tasks. Imagine them as a tree-like structure, where each decision splits the data into smaller subsets based on the value of input features. This process continues, creating branches, until it reaches a final decision at a leaf node. The tree uses criteria like Gini impurity or information gain to decide the best way to split the data at each step, ensuring it makes the most accurate predictions possible.
Unsupervised Learning Algorithms
In unsupervised learning, the algorithm is given data without explicit instructions on what to do with it. The goal is to find hidden patterns or intrinsic structures in the data.
Common Unsupervised Learning Algorithms
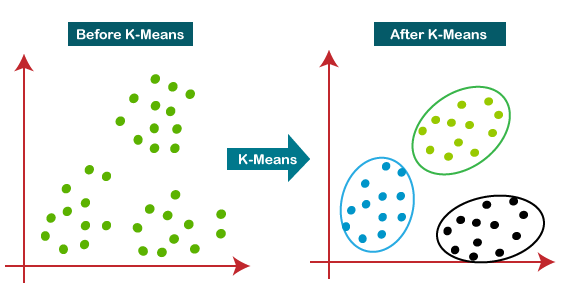
K-Means Clustering
K-Means Clustering is for grouping data into a specified number (k) of clusters. It works by first assigning each data point to the nearest cluster center. Then, it updates the cluster centers based on the average position of the points assigned to them. This process of assigning points and updating centers repeats until the clusters stabilize, or converge. A key part of using K-Means is deciding the number of clusters (k) before you start.
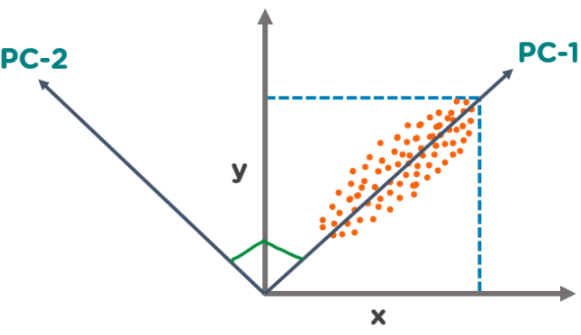
Principal Component Analysis (PCA)
Principal Component Analysis (PCA) is a handy dimensionality reduction technique. It works by transforming your data into a new set of components that are linearly uncorrelated and ordered by how much variance they capture. Essentially, PCA helps to reduce the number of features in the dataset while retaining most of the important information, making it easier to visualize and analyze without losing significant details.
Reinforcement Learning Algorithms
Reinforcement learning involves an agent that learns by interacting with its environment, receiving rewards or penalties for its actions. The goal is to learn a policy that maximizes cumulative rewards.
Common Reinforcement Learning Algorithms
Q-Learning
Q-Learning is a value-based method used in reinforcement learning to figure out the best actions to take in different situations. It relies on a Q-table to store the values of state-action pairs, which get updated based on the rewards received and the estimated future rewards. The process involves the agent exploring the environment and learning from its experiences, iterating over multiple episodes to refine the Q-values and improve its decision-making over time.

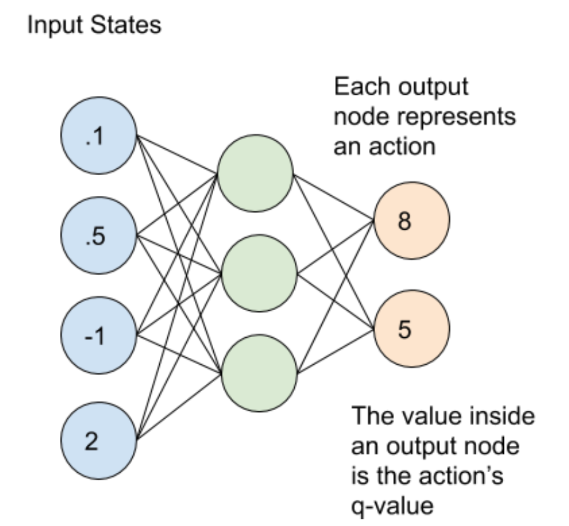
Deep Q-Networks (DQN)
Deep Q-Networks (DQN) combine the strengths of Q-learning with deep neural networks to tackle complex, high-dimensional state spaces, such as those found in video games. Instead of a Q-table, DQN uses a neural network to approximate the Q-values, enabling the agent to learn effective policies for navigating intricate environments. The training process is stabilized through techniques like experience replay, which stores and reuses experiences, and target networks, which help maintain consistent learning.